TL;DR: We propose a novel learning-from-human framework that explicitly models intention to capture the causal structure of manipulation behavior.
Abstract
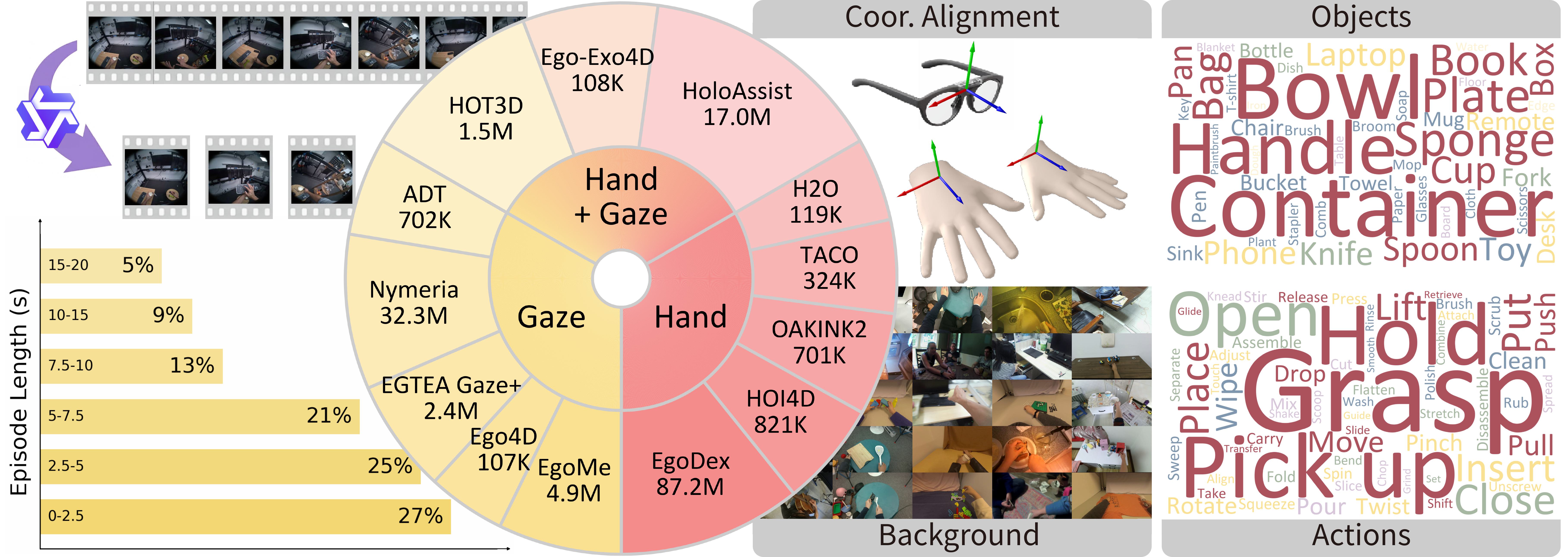
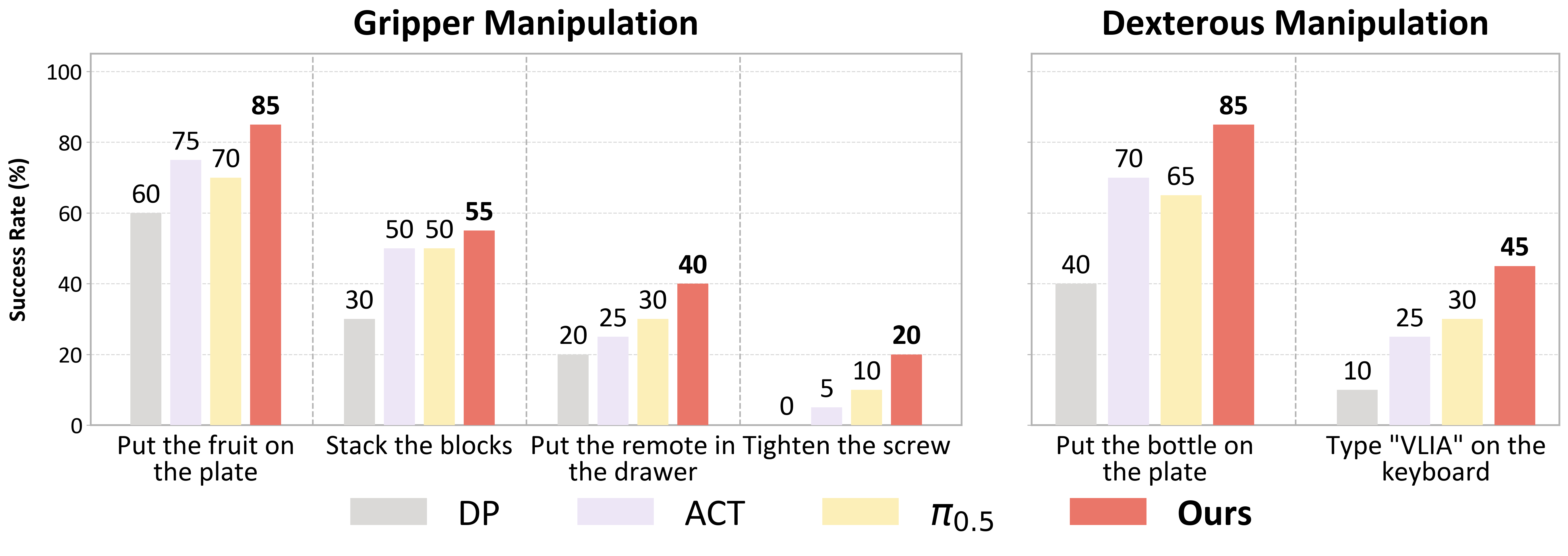
Embodied foundation models have achieved significant breakthroughs in robotic manipulation, but they heavily rely on large amounts of robot demonstrations. Although recent works have explored leveraging human data to alleviate this dependency, effectively extracting transferable knowledge remains a significant challenge due to the inherent human-robot embodiment gap. To address this, we argue that the intention underlying human actions can serve as a powerful intermediate representation to bridge this gap. In this paper, we introduce VLIA, a novel framework that explicitly learns and transfers human intention to facilitate robotic manipulation. Specifically, we model intention through gaze, as it naturally precedes physical actions and serves as an observable proxy for human intent. VLIA is first pretrained on a large-scale egocentric human dataset to capture human intention and its synergy with action, followed by finetuning on a small set of robot and human data. During inference, the model adopts a Chain-of-Thought reasoning paradigm, sequentially predicting intention before executing the action. Extensive evaluations including simulations and real-world experiments, long-horizon and fine-grained tasks, as well as few-shot learning and robustness assessments, demonstrate that our method outperforms existing baselines, exhibits exceptional generalization, and achieves state-of-the-art performance.